העדפות
הפרטיות חשובה לנו, ולכן יש לך אפשרות להשבית סוגים מסוימים של אחסון שייתכן שאינם נחוצים לתפקוד הבסיסי של האתר. חסימת קטגוריות עלולה להשפיע על חווית השימוש שלך באתר. מידע נוסף

הפרטיות חשובה לנו, ולכן יש לך אפשרות להשבית סוגים מסוימים של אחסון שייתכן שאינם נחוצים לתפקוד הבסיסי של האתר. חסימת קטגוריות עלולה להשפיע על חווית השימוש שלך באתר. מידע נוסף
Make your Squidex content visible to Google and AI search. Model schemas, expose clean fields through the REST and GraphQL APIs, add JSON-LD and llms.txt so ChatGPT, Perplexity, Claude, and Gemini cite the pages your front end renders.
Want the content you manage in Squidex to appear inside AI answers, not only classic search results? Squidex is an open-source, API-first headless CMS built on .NET: you define schemas, fill structured content, and serve it through a per-schema REST API and a GraphQL endpoint to any front end you choose. That clean separation of content and presentation is a strong base for generative engine optimization (GEO). Start with a baseline geo seo audit and track every gain in a living geo seo dashboard. This guide shows how to model, render, and annotate Squidex content so Google and assistants like ChatGPT, Perplexity, Claude, and Gemini understand, trust, and cite your pages.
Classic SEO still drives traffic, and now assistants summarize the web and surface a short list of cited sources. Generative Engine Optimization is the practice of becoming one of those sources. Squidex helps because content lives as structured, typed fields rather than tangled markup: a single article exists once and feeds web, app, and assistant surfaces through the API. When your front end renders that content as clean HTML and you expose precise fields, models map your topics, products, and expertise with confidence.
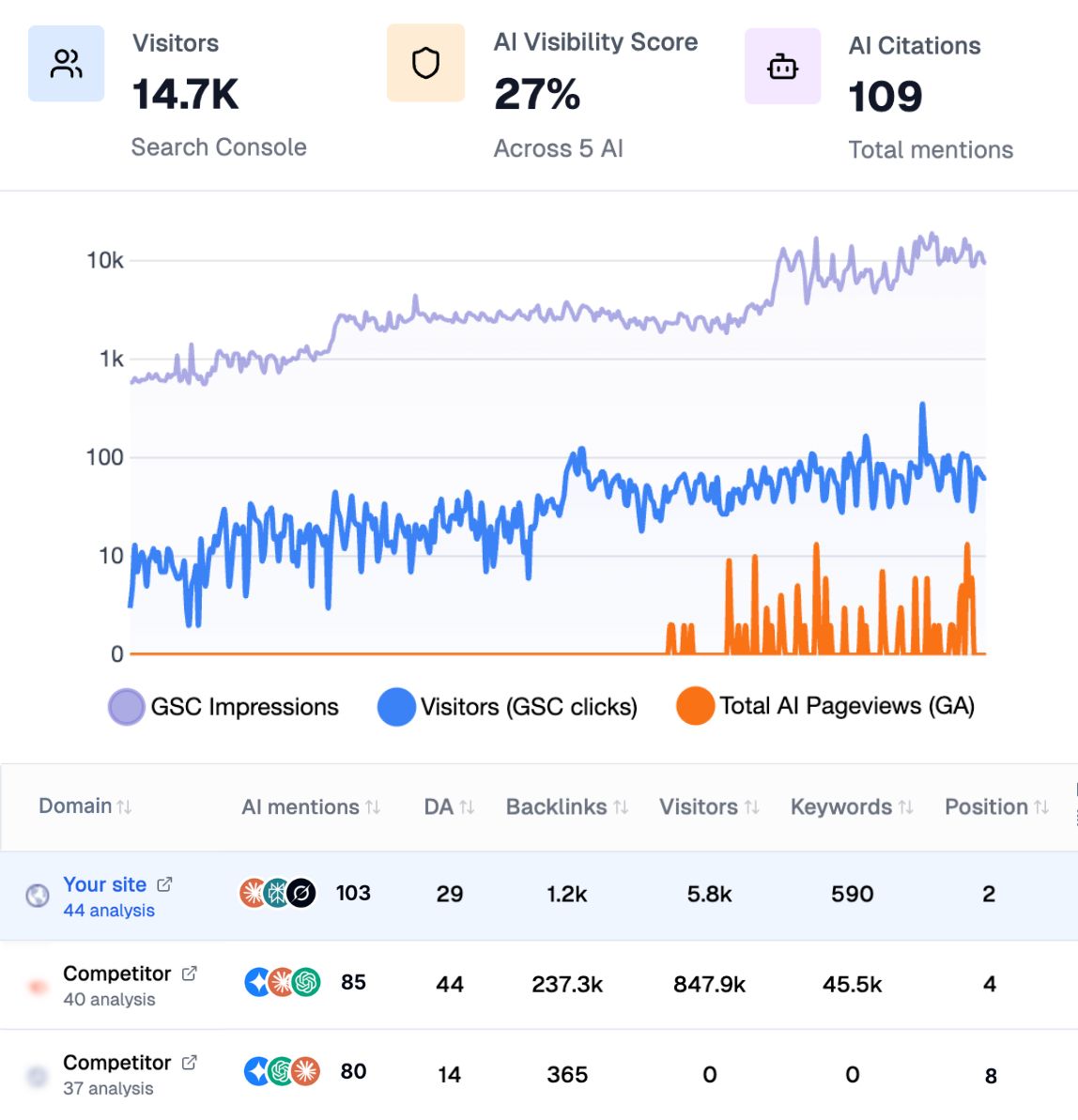
Begin with a benchmark. Ask the leading assistants the real questions your audience asks, then record whether you are cited, which URLs appear, and how competitors are framed. Follow brand citations with ai mention tracking, study the references you earn through ai cited backlinks, and run a baseline geo seo audit to map the entities already associated with your brand.
In GEO, user intent arrives as prompts. Collect the exact wording people use in chat, voice, and agents, then group it by task: learn, compare, apply, and resolve. Expand coverage with the query fan-out tool and prioritize topics with keyword research. For each group, choose one canonical page to be cited, and make it concise, quotable, and supported by explicit evidence.
Treat Squidex schemas as your entity backbone. Create schemas for Articles, Guides, Products, FAQs, Authors, and a Glossary, and give each typed fields: title, slug, summary, body, image, published date, author reference, and tags. Map those fields to schema.org properties such as name, description, image, datePublished, author, and sameAs. Squidex supports references between schemas, so you link an article to its author and topic cleanly, which keeps your entities consistent across every surface.
Squidex delivers content through APIs; your front end renders it. Choose server-side rendering or static generation so the pages you want cited return complete HTML on first request, without client-side hydration. Pull content with the REST API or GraphQL, render titles, headings, and body into semantic markup, and confirm the full text appears in the raw page source. Squidex serves images through its asset pipeline with resizing, which keeps pages fast.
Add schema fields for the SEO title, meta description, and canonical URL, then render them in your front end head. Keep URLs clean and keyword bearing through your routing. Apply meta robots rules to keep thin or duplicate pages out of the index, and set Open Graph and Twitter tags from the same fields so social previews match the page intent and the main copy. Because the values live in structured content, they stay consistent across builds.
Generate JSON-LD in your front end from Squidex fields. Use Article plus WebPage and BreadcrumbList for content pages, Product with offers for product pages, HowTo for tutorials, and FAQPage for question blocks. Add a site-wide Organization block with logo, contactPoint, foundingDate, and sameAs links to your verified profiles. Since the data comes straight from typed fields, your structured data stays accurate and complete on every render.
Open each article with a two sentence summary that resolves the query, then expand with a scannable outline. Add explicit question and answer blocks that mirror real prompts, and keep each answer between 50 and 120 words. For procedures, list materials, steps, and time required in HowTo format. Speed up production of these citable drafts with the blog article generator, then refine each entry in the Squidex editor.
Generate a sitemap.xml from your published content and submit it in Google Search Console. In robots.txt, allow the routes that hold citable content and disallow noise. Add an llms.txt file at the root to signal preferred crawl rules for AI agents, the priority URLs you want cited, and your reuse terms. Because Squidex exposes a content API, you can build these files automatically from the same data that powers your pages.
Build topic hubs that group related pages and define your canonical answers. Use breadcrumbs to express hierarchy and add contextual inline links with descriptive anchors, accelerated with a topical cluster generator. Squidex references make these connections explicit in your data model. If other parts of your stack run elsewhere, apply the same principles on headless siblings like strapi, directus, and contentful.
GEO still rests on authority. Earn citations from credible publications, original research, and the communities your audience trusts. Publish under named authors with real bios stored as an Authors schema, show credentials, and keep an About page that states who you are and why you are reliable, which strengthens E-E-A-T. Track progress with a domain authority tracker and study rival coverage with seo competitor spy.
Squidex exposes a public API with a per-schema REST endpoint to create content, so Sorank connects through a Make.com webhook bridge: each article Sorank generates is sent to a Make.com scenario, and Make publishes it to Squidex using a generic HTTP module that posts to the contents endpoint of your target schema. There is no dedicated Make.com app, and the webhook plus generic HTTP route automates publishing end to end. Map Sorank fields to your schema, authenticate with a client, and produce optimized drafts fast with the blog article generator.
Track which prompts trigger your brand, which pages get cited, and where competitors win the answer. Compare positions with keyword research, watch your standing on a geo leaderboard, and attribute conversions from assistants with tagged landing pages and unique UTMs.
Squidex gives you structured, API-first content; GEO gives you the strategy to get cited. When your schemas carry typed fields, your front end emits complete HTML, and your pages carry JSON-LD and citable answers, assistants quote you with confidence. Model clean schemas, render server-side, add JSON-LD, and publish through the API, then let Sorank drive audits, content, and links.
Squidex performs well for GEO because it is an API-first headless CMS: content lives as typed fields in schemas and is served through a per-schema REST API and GraphQL to any front end. Render that content server-side or as static pages so it returns complete HTML to crawlers on first request. Map fields to schema.org properties, generate JSON-LD from them, and use references to link articles, authors, and topics cleanly. Add clean canonical URLs, a generated sitemap, and an llms.txt file so assistants like ChatGPT, Perplexity, Claude, and Gemini can reach and cite your pages with confidence.
Write answer-first content mapped to real prompts. Open each entry with a two-sentence summary, then a scannable outline, and keep paragraphs under 120 words. Use a strict heading hierarchy, explicit FAQ blocks with 50 to 120 word answers, and a clear facts section. Anchor every claim to a source and generate JSON-LD (Article, FAQPage, HowTo, Organization) from your Squidex fields in the front end. Build hubs that link related pages with descriptive anchors, modeled as references between schemas, which signals the topical depth that models recognize as authoritative and quote.
Squidex exposes a public API with a per-schema REST endpoint to create content, so Sorank connects through a Make.com webhook bridge rather than a native connector. Each article Sorank generates is sent to a Make.com scenario, and Make publishes it to Squidex with a generic HTTP module that posts to the contents endpoint of your target schema. There is no dedicated Make.com app, and the webhook plus generic HTTP route automates publishing end to end. Map Sorank fields to your schema and authenticate with a client first. Beyond publishing, Sorank runs GEO and SEO audits, tracks AI mentions across ChatGPT, Perplexity, and Gemini, monitors competitors, and suggests optimizations from one dashboard.








.svg)
.svg)

