التفضيلات
خصوصيتك مهمة بالنسبة لنا، لذلك لديك خيار تعطيل أنواع معينة من التخزين التي قد لا تكون ضرورية للوظائف الأساسية للموقع. قد يؤثر حظر الفئات على تجربتك في الموقع. مزيد من المعلومات

خصوصيتك مهمة بالنسبة لنا، لذلك لديك خيار تعطيل أنواع معينة من التخزين التي قد لا تكون ضرورية للوظائف الأساسية للموقع. قد يؤثر حظر الفئات على تجربتك في الموقع. مزيد من المعلومات
Make your Payload CMS site visible to Google and AI search. Use collections, fields, a Next.js front end, JSON-LD, and llms.txt so ChatGPT, Perplexity, Claude, and Gemini cite your pages.
Want your Payload CMS site to surface inside AI answers, not only in the classic ten blue links? Payload CMS is a code-first, TypeScript headless CMS you self-host alongside your application, where editors work with collections and globals defined as typed fields, and developers read and write content through REST, GraphQL, and a server-side Local API, a schema-driven core that makes it a strong base for generative engine optimization (GEO). Start with a baseline geo seo audit and let every gain compound inside a living geo seo dashboard. This guide shows how to model, render, and annotate Payload so Google and assistants like ChatGPT, Perplexity, Claude, and Gemini understand and cite your pages.
Visibility now splits in two: the ranked links you already chase, and the short roster of sources that ChatGPT, Perplexity, Claude, and Gemini cite when they answer. Generative Engine Optimization is the practice of joining that roster. Payload fits the brief because content is defined as code: every collection has typed fields, validation, and relationships, backed by MongoDB or Postgres, so each document behaves like a clean structured record rather than a freeform page. Because Payload is headless, you render it through a fast modern front end and keep total control over the semantic HTML that models read as distinct entities.
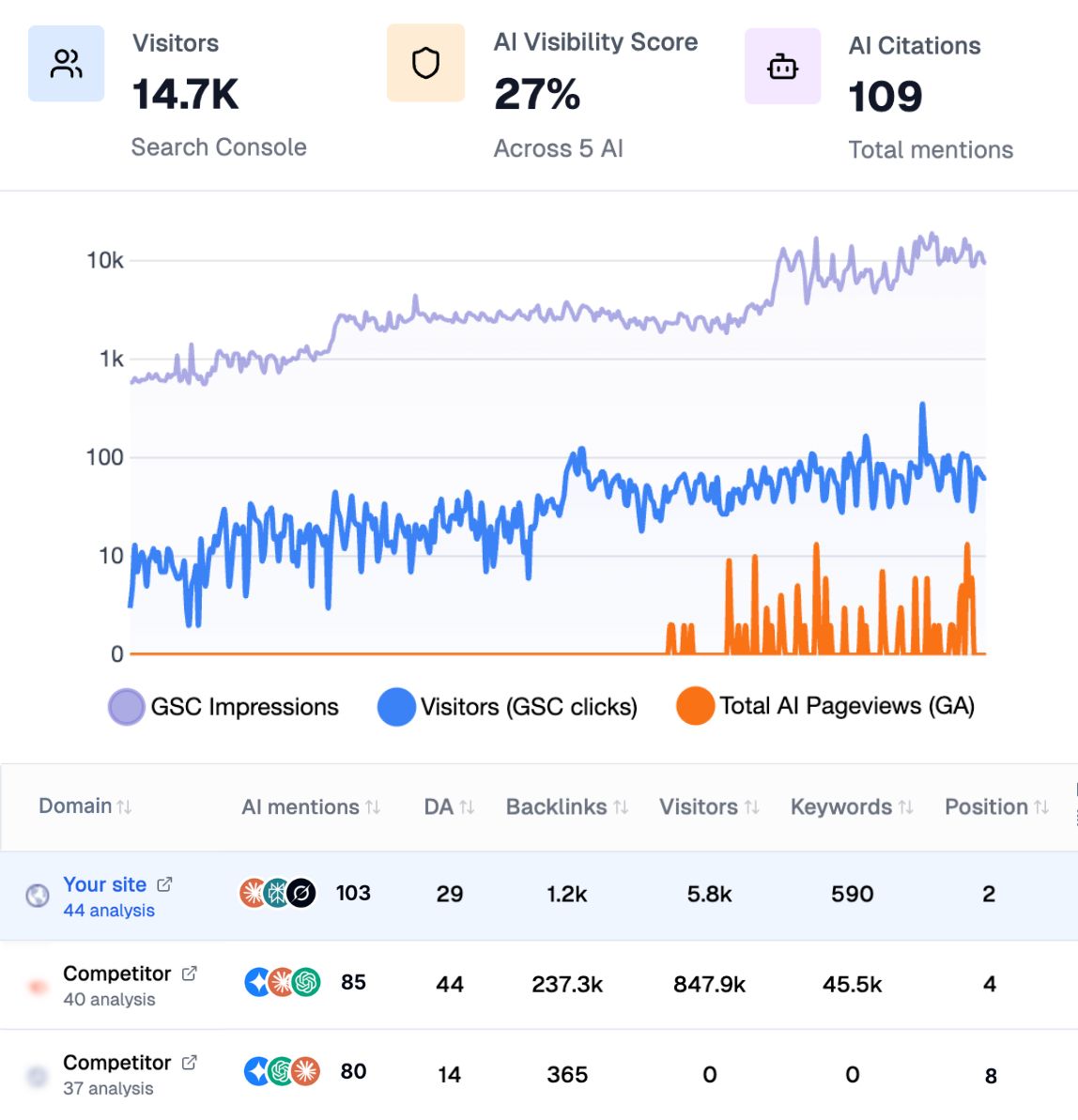
Measure before you build. Put the real questions your audience asks to the leading assistants, then log whether your pages appear and which URLs they cite. Follow brand citations with ai mention tracking, study the references you already earn through ai cited backlinks, and run a detailed geo seo audit to map the entities (brand, people, products) already linked to your domain. This benchmark tells you which collections and documents to prioritize first.
In GEO, intent arrives as complete prompts, not clipped keywords. Collect the exact wording people use in chat and voice, then group it by task: learn, compare, choose, and fix. Broaden coverage with the query fan-out tool and rank the topics with keyword research. For each cluster, designate one canonical Payload document as the page you want cited, then make it concise, quotable, and backed by explicit evidence so a model can pull a passage without bending its meaning.
Treat your collections as the entity backbone. Define collections such as Posts, Categories, Products, Team, FAQs, and a Glossary, give each typed fields, and connect them with relationship fields. Map your fields to schema.org properties like name, description, image, datePublished, author, about, and sameAs, and store SEO metadata in a dedicated group on every collection. Because the schema is code, canonical names and facts stay uniform across the site, and the official SEO plugin standardizes title and description fields. That repeatable depth is the topical authority answer engines reward when choosing a source.
Payload is headless, so pair it with a fast front end such as Next.js, Nuxt, or Astro and render pages on the server. Payload ships tightly with Next.js, so you fetch documents through the Local API at build or request time and emit clean, semantic HTML with no client-side hydration tax on content. Use static generation or incremental regeneration for articles, serve assets through a CDN, and cache aggressively. Fast pages with crawlable markup raise crawl coverage and how often assistants quote you.
Drive metadata from your collection fields: add the official SEO plugin or your own SEO group so every document carries a precise title, a meta description, and Open Graph values that match the body. In your front end, render those fields into the document head, build clean entity-rich URLs from your slugs, and print canonical tags to fold duplicates and paginated archives into one address. Apply meta robots to keep thin tag listings and filtered views out of the index, so assistants read one coherent meaning per page.
On Payload, JSON-LD lives in your front-end framework, not the admin panel. In your Next.js, Nuxt, or Astro page component, output a script block of type application/ld+json populated from the document you fetched, so each page emits structured data built from its own fields. Use Article with WebPage and BreadcrumbList for content, Product with offers on commerce pages, HowTo for tutorials, and FAQPage for question blocks. Add a site-wide Organization graph with logo, contactPoint, and sameAs links, so assistants confirm facts and tie your pages to recognized entities.
Create explicit question and answer blocks that mirror real prompts, and add a dedicated FAQ field group or blocks field so editors reproduce the pattern on every relevant document. Keep each answer between 50 and 120 words, link to the matching internal page, and cite one authoritative outbound source. For procedures, lay out materials, ordered steps, and the time required in HowTo form. These compact formats strip out ambiguity and make it simple for an assistant to quote your Payload pages while keeping the meaning intact.
Generate an XML sitemap in your front end listing every published document, then submit it in Google Search Console. In robots.txt, allow the routes that hold citable content and disallow the admin panel and API endpoints. Publish an llms.txt file at your domain root that states preferred crawl rules for AI agents, your priority URLs, and your reuse terms. This file is increasingly honored and signals clear provenance to the models that cite sources.
Build topic hubs that gather related documents and define your canonical answers, and use a navigation global plus breadcrumbs for a clean hierarchy. Add contextual inline links with descriptive anchors, and connect every document to its parent hub and sibling topics through relationship fields. Speed up the mapping with a topical cluster generator. If parts of your stack run elsewhere, use the same approach on strapi, directus, webflow, and shopify.
GEO still runs on authority. Earn citations from credible publications, primary research, and the TypeScript and developer communities that orbit Payload projects. Publish under named experts, surface reviewer credentials, and keep detailed bio pages and an About page that strengthen E-E-A-T. Track your standing over time with a domain authority tracker, and display a clear last-updated date on strategic documents so both Google and assistants read your content as current and well maintained.
Payload CMS exposes a public API: every collection automatically gets REST and GraphQL endpoints that create documents, though it has no dedicated Make.com app. So Sorank connects through a Make.com webhook bridge, where each article it generates is sent to a Make.com scenario, and Make publishes it to Payload using Make.com's generic HTTP module to POST against your collection endpoint with an API key. There is no native Sorank connector yet, and this route automates publishing. Draft optimized articles fast with the blog article generator, then push them live on a schedule. Validate the create-content call on your live instance first, and fall back to Sorank's self-hosted blog if your configuration restricts it.
Track which prompts trigger your brand, which documents get cited, and where competitors win. Benchmark yourself with seo competitor spy, watch your position on a geo leaderboard, and attribute assistant-driven visits with tagged landing pages and UTMs. Review the data after each new schema, content cluster, and link campaign, and repeat monthly so GEO becomes a measurable, compounding growth engine.
Payload CMS gives you a code-first, typed content model and full control over your front-end markup; GEO gives you the strategy to put it in front of answer engines. When your documents expose clear entities, precise metadata, and reliable evidence, assistants cite you with confidence. Set up structured collections, a fast server-rendered front end, JSON-LD, and citable answers, then let Sorank drive the audits, content, and links so your brand becomes the source models prefer to cite in 2026 and beyond.
Payload CMS is an excellent GEO foundation because content is defined as code: every collection has typed fields, validation, and relationships backed by MongoDB or Postgres, so your topics, people, and products read as clean entities. Because it is headless, you render through a fast front end such as Next.js with server rendering, giving you full control over semantic HTML. Add the official SEO plugin for precise titles and Open Graph values, emit JSON-LD from your front end, build clean URLs from slugs, generate an XML sitemap, and publish an llms.txt file. With that setup, ChatGPT, Perplexity, Claude, and Gemini can reach, parse, and cite your content reliably.
Write answer-first pages mapped to real prompts. Open each one with a two-sentence summary, follow with a scannable outline, and keep paragraphs under 120 words. Hold a strict heading hierarchy (H2 over H3), add explicit FAQ blocks with 50 to 120 word answers, and anchor every claim to a source. Emit JSON-LD (Article, FAQPage, HowTo, Organization) from your front-end framework, and link internally so hubs connect to related documents through relationship fields. A dedicated FAQ field group or blocks field lets editors reproduce the pattern at scale, signaling the topical depth that answer engines recognize as authoritative and safe to quote.
Payload CMS exposes a public API: every collection automatically gets REST and GraphQL endpoints that create documents, with no dedicated Make.com app, so Sorank connects through a Make.com webhook bridge. Each article Sorank generates is sent to a Make.com scenario through a webhook, and Make publishes it to Payload using Make.com's generic HTTP module to POST against your collection endpoint with an API key. Beyond publishing, Sorank runs GEO and SEO audits, tracks AI mentions across ChatGPT, Perplexity, and Gemini, monitors competitors, and suggests content optimizations from one dashboard. Validate the create-content call on your live instance first, and fall back to Sorank's self-hosted blog if your configuration restricts it.








.svg)
.svg)

