


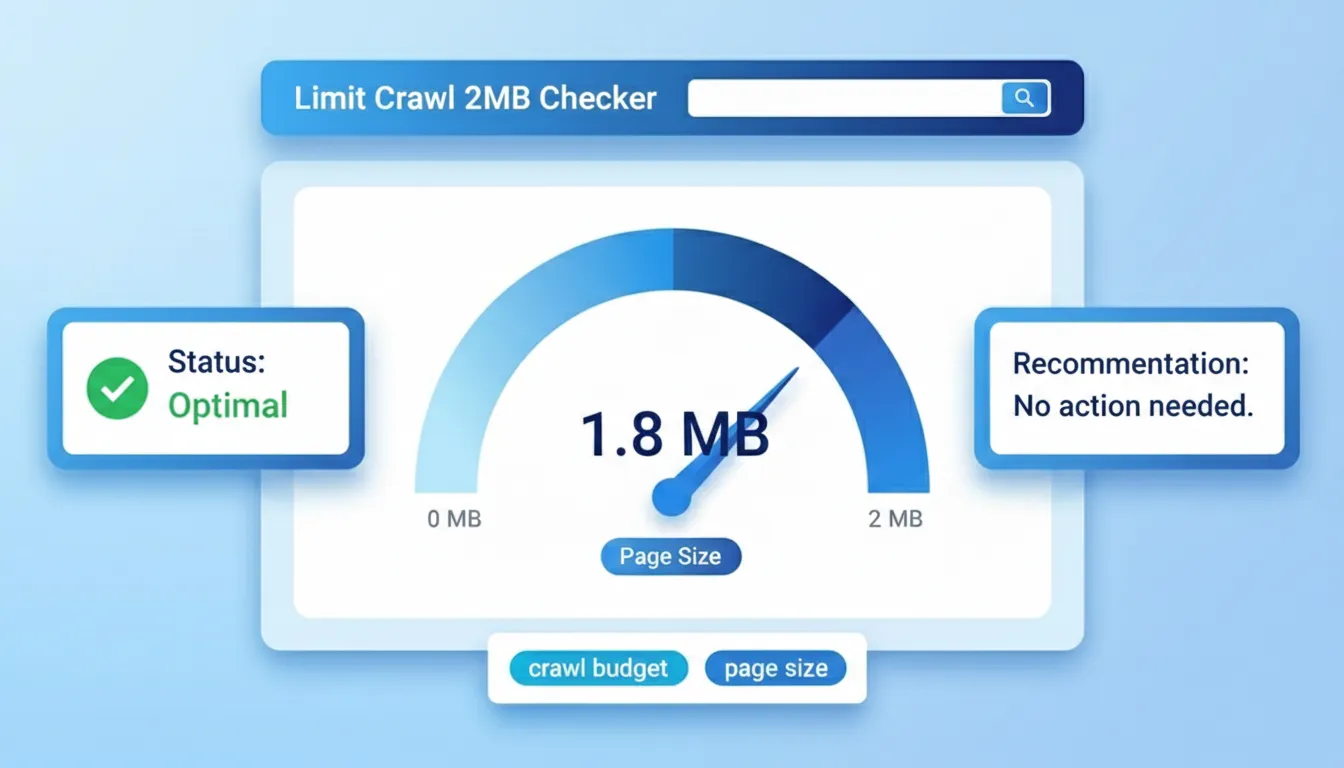
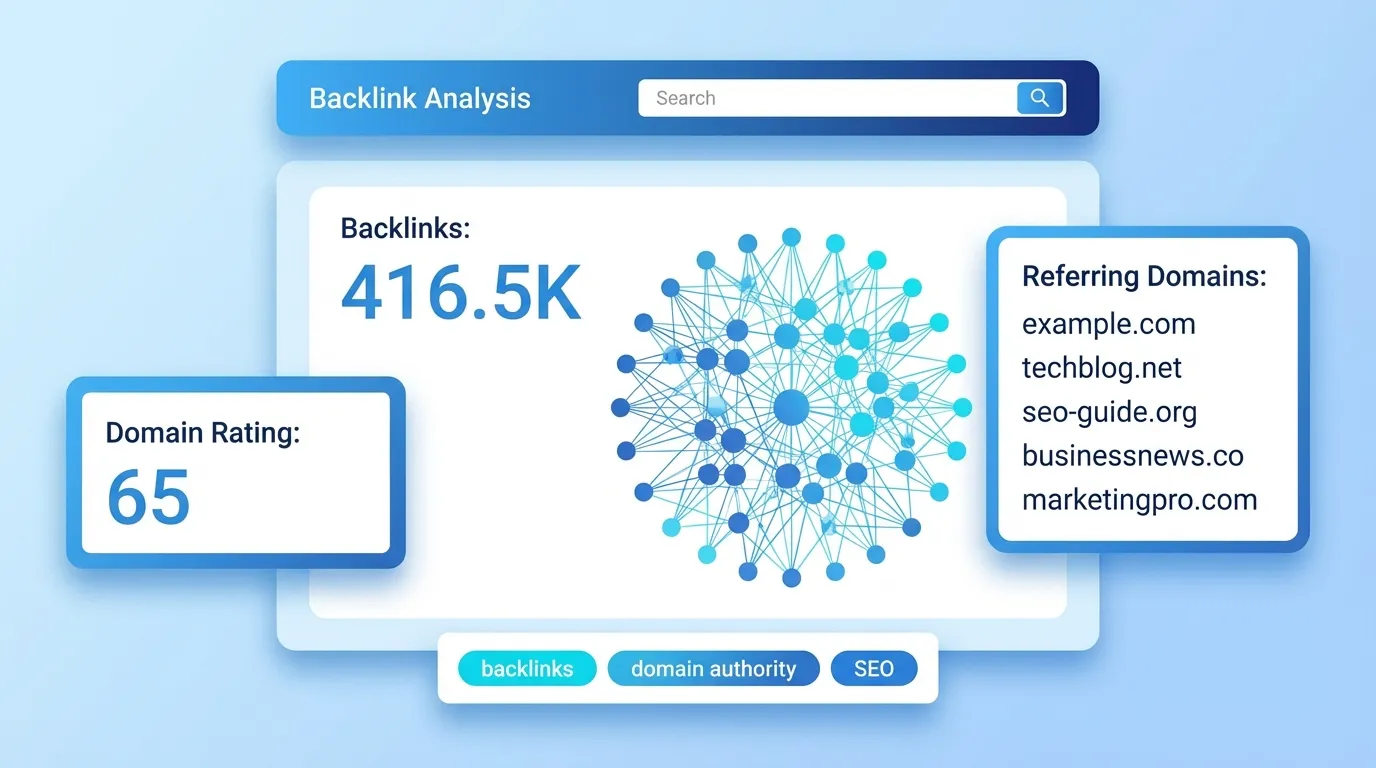
Der Robots.txt Checker liest die robots.txt-Datei jeder Domain, validiert ihre Syntax und zeigt genau, welche Crawler - einschließlich aller wichtigen KI-Bots - erlaubt oder blockiert sind. Geben Sie Ihre Domain in das Tool oben ein, um eine sofortige Diagnose zu erhalten.
Was robots.txt ist und warum es für GEO wichtig ist
Robots.txt ist eine einfache Textdatei im Stammverzeichnis Ihrer Website, die Crawlern mitteilt, welche Seiten sie besuchen dürfen und welche nicht. Für traditionelles SEO steuert sie das Crawl-Budget. Für GEO (Generative Engine Optimization) bestimmt sie, ob ChatGPT, Perplexity, Gemini und andere KI-Suchmaschinen Ihre Inhalte lesen und zitieren können.
Eine einzige falsch platzierte Wildcard-Regel in Ihrer robots.txt kann alle KI-Crawler gleichzeitig blockieren -- oft ohne dass Sie es bemerken, weil Ihre Google-Rankings nicht betroffen sind. Das Ergebnis: Sie sind für KI-gesteuerte Suche unsichtbar, obwohl Ihre Seiten technisch einwandfrei sind.
Was das Tool oben prüft
- Syntaxvalidierung: erkennt fehlerhafte User-agent-Blöcke, ungültige Pfade und Zeichenkodierungsfehler.
- KI-Bot-Zugang: prüft explizit den Status für GPTBot (OpenAI), OAI-SearchBot (SearchGPT), PerplexityBot, Google-Extended, ClaudeBot und Meta-ExternalAgent.
- Sitemap-Deklaration: bestätigt, ob eine Sitemap-Direktive vorhanden und die referenzierte URL erreichbar ist.
- Globale Blockierungsregeln: erkennt
Disallow: /-Direktiven, die versehentlich Ihren gesamten Content sperren.
Ergebnisse interpretieren und handeln
- KI-Bot blockiert: finden Sie die spezifische Disallow-Regel und entfernen oder engen Sie sie ein. Wenn Sie einen Bot aus gutem Grund blockieren, bestätigen Sie, dass es sich um eine bewusste Entscheidung handelt.
- Syntaxfehler: ein einziger Fehler kann dazu führen, dass Crawler den gesamten Regelblock ignorieren. Korrigieren Sie ihn und testen Sie erneut.
- Keine Sitemap deklariert: fügen Sie eine
Sitemap:-Direktive am Ende der Datei hinzu, damit alle Crawler Ihre Site-Struktur effizient entdecken.
Referenzwert: Warum KI-Crawler-Zugang wichtig ist
KI-Overviews erscheinen jetzt bei rund 31 % der Google-Anfragen (2025). Traffic von KI-Plattformen wie Perplexity konvertiert mit ca. 7 %, fast dreimal so oft wie organischer Such-Traffic. Eine einzige fehlerhafte robots.txt-Regel, die KI-Bots blockiert, schließt Sie von diesem gesamten Traffic-Kanal aus.
Für die laufende Überwachung Ihrer KI-Sichtbarkeit und Zitierungsperformance überwacht Sorank Ihren GEO-Status automatisch.








.svg)
.svg)

